
Below, I discuss and analyse pre-processing decisions in relation to an often-used application of text analysis: scaling. Here, I’ll be using a new tool, called preText (for R statistical software), to investigate the potential effect of different pre-processing options on our estimates. Replication material for this post may be found on my GitHub page.
Feature Selection and Scaling
Scaling algorithms rely on the bag-of-words (BoW) assumption, i.e. the idea that we can reduce text to individual words and sample them independently from a “bag” and still get some meaningful insights from the relative distribution of words across a corpus.
For the demonstration below, I’ll be using the same selection of campaign speeches from one of my earlier blog posts, in which I used a couple of simple off-the-shelf tools to measure linguistic complexity in campaign speeches by now-president Donald Trump, and the then Democrat nominee Hilary Clinton. Transcripts of Hillary Clinton’s speeches are available here. The press releases section of Donald Trump’s website contains speeches in the form of “remarks as prepared for delivery”.
In scaling models, we reduce our corpus of texts to a document-term-matrix (DTM) and consider the variation in term use across the matrix. There are a considerable number of pre-processing decisions we can make at this stage. Here, I’ll follow Denny and Spirling’s working paper on pre-processing for unsupervised learning, and use their preText package for R to show the effects of punctuation, numbers, lowercasing, stemming, stop word removal, n-gram inclusion and infrequently used terms. The key challenge here is to retain meaningful features.
PreText allows us to estimate the effect of pre-processing on the composition of our DTM by considering changes to the ranking in distance pairs between the word-frequency-matrix of individual documents in the DTM between different applications. In each step, we measure the similarity (e.g. cosine or Euclidean) between the documents in the DTMs, and look at the degree to which the order of pairwise distance changes. Subsequently, we can consider the top k pairs that change in rank order the most, and calculate the rank difference for each pair k between a specification and all other specification. We can then take the mean of these differences across all top pairs k.
Results
To generate a measure of influence for a pre-processing decision (i.e. a measure of its effect on our DTM), we can take this preText score as a DV and run a linear regression with all pre-processing decisions included as dummies. For my data, the results are shown in the graph below.
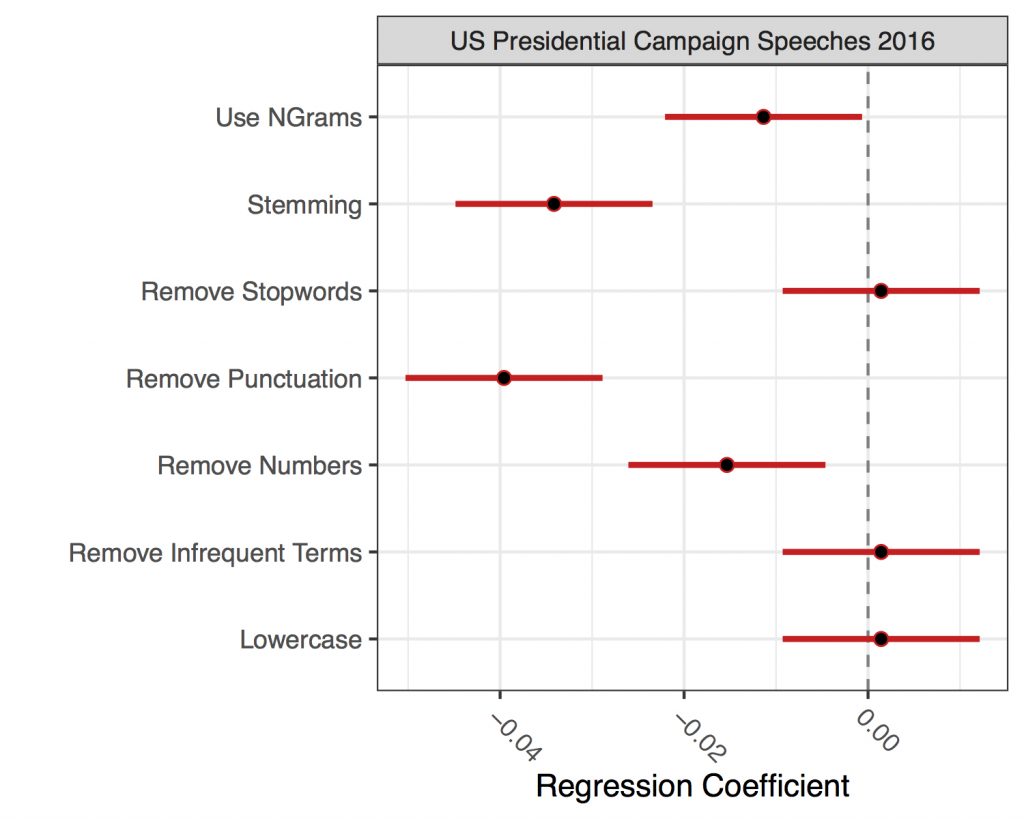
Negative coefficients imply that the pre-processing decision does not produce unusual results; and vice versa (in other words: we should be worried about the estimates that fall to the right of the zero line).
Overall, it seems that our different feature selection options would not substantively change our results in a scaling exercises for this corpus. The preText coefficients are below zero in some cases, and all 95 per cent confidence intervals include zero.
Still, even if we do find that a pre-processing decision has a strong effect (i.e. produces an unusual result), this does not mean that we should not use it. All in all, feature selection should always be informed by theory.
And as the set of tools that we have at our disposal to improve pre-processing quality grows, so should the time we spend thinking about what we are aiming to measure, and what features should therefore be the focus of our attention.
Comments


{kind=link}
{kind=link}