
About thirty major pieces of government legislation are produced annually in the UK. As there are five main opportunities to amend each bill (two stages in the Commons and three in the Lords) and bills may undergo hundreds, even thousands, of amendments, comprehensive quantitative analysis of legislative changes is almost impossible by manual methods. We used insights from bioinformatics to develop a semi-automatic procedure to map the changes in successive versions the text of a bill as it passes through parliament. This novel tool for scholars of the parliamentary process could be used, for example, to compare amendment patterns over time, between different topics or governments, and between legislatures.

Parliamentary amendments
A major role of parliament is to scrutinize and amend legislation. Analysis of legislative amendments throws light on the political process (Russell 2013). It has been suggested, for example, that UK legislation is increasingly poorly prepared, with more government amendments being used to repair defects during the passage of a bill, reducing the quality of parliamentary scrutiny (Foster 2005).
Such assertions are difficult to test, however, as no effective methods for quantifying legislative changes yet exist. The few existing quantitative studies of legislative amendments generally include only a few pieces of legislation (e.g. Hood and Dixon 2015 (29 UK bills); Kreppel 1999 (24 EU legislative proposals)). Exceptions are Tsebelis and colleagues (2001) who studied amendments to 231 EU legislative proposals, and Martin and Vanberg (2005) who looked at changes to 336 German and Dutch bills. This lack of quantitative research is partly because the process of detecting agreed amendments (e.g. from Hansard reports and minutes of committee proceedings) is extremely laborious. There is also little administrative data available: for instance the UK Public Bill Office provides statistics on the number of amendments made in the House of Lords, but there is no equivalent information from the House of Commons.
Bioinformatics – the study of mutation
Drawing on my background in Biochemistry, it struck me that a bill’s passage through parliament can be likened to biological evolution, which proceeds by the accumulation of mutations. DNA encodes genetic information in long sequences of four ‘bases’ (A, C, G, T). Procedures for comparing DNA sequences, a field known as bioinformatics, can be used to identify mutations. For instance, van’t Hof and colleagues (2016) showed recently that the dark colouration of the peppered moth is caused by the insertion of 22,000 bases into the DNA of a gene involved in wing development (Figure 1).
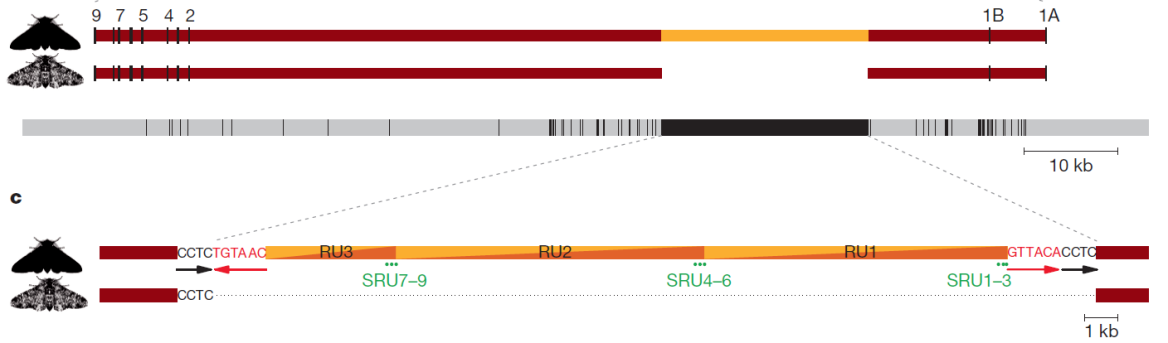
Part of Figure 1 from van’t Hof et al. (2016) showing the mutation for wing colouration in the British peppered moth.
Semi-automated procedure for detecting ‘mutations’ to legislation
Like a gene, a bill “mutates” when the information it contains is altered by insertion, deletion, and substitution of text. Bills typically contain less than a megabyte of data, and should be amenable to comparison methods similar to those used in bioinformatics. Accordingly, we developed a novel procedure which generates a visual display of the evolution of successive versions of a bill (see Figure 2). As well as the graphical output, detailed reports are produced of the number, length, and content of the text differences which can be used for further statistical and content analysis.
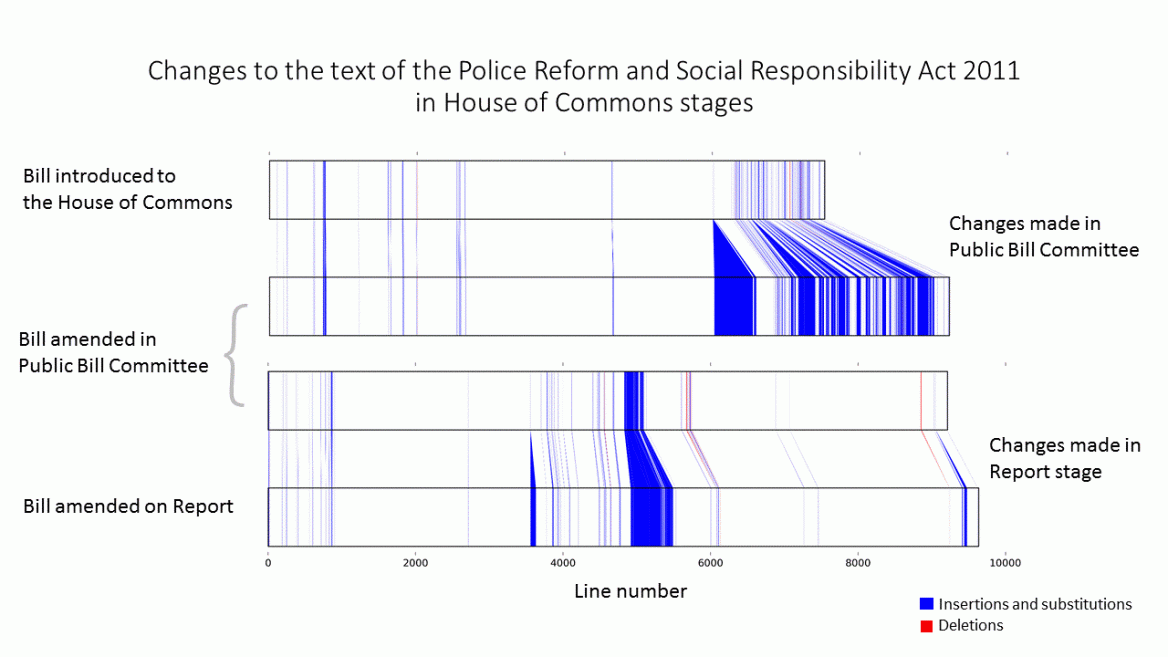
In order to exclude irrelevant differences between versions such as page headers and renumbering of clauses, we developed a Python script to ‘clean up’ texts so that conventional text-comparison software (Winmerge, in this case) could be applied. The clean-up process required some user input and, even so, failed to exclude certain types of irrelevant difference such as typo corrections and some formatting changes. Such differences had to be screened out manually before a second Python script was used to analyse the list of differences (the ‘patch file’) and produce the graphical output. Hence the process is ‘semi-automated’ rather than fully automatic. Nevertheless, the process can be used to map text alterations in a tiny fraction of the time that the same process would take by hand. Further details of the procedure are in my slides.
The number of text differences detected by this procedure is not precisely the same as the number of parliamentary amendments. This is because several parliamentary amendments may alter the same short section of text (resulting in a single difference being detected), or alternatively a single parliamentary amendment can result in several differences (as, for example, when a long section of text replaces a similar one). Our procedure, however, accurately portrays the actual cumulative effect of the parliamentary amendments on the text.
Note: this article was also published on the LSE’s British Politics and Policy Blog and on Ruth’s personal blog. It summarises her presentation (co-authored with Jonathan A. Jones) to the Political Studies Association Political Methodology Group Conference at University College, London, on 27 June 2016 (slides available here).
Comments




{kind=link}
{kind=link}